
If there’s one thing we like doing on this website, it’s ranking things. We like ranking things so much it’s become a meme in the forums for just how often it happens in threads. From albums to food, to the new sub-genre of brackets, ranking has become a core part of our little culture. It’s also part of what we do on a pretty regular basis here on the editorial side of things. We’ve got our yearly most anticipated lists and the mid and end of the year “best-of lists.” Back in the days of AbsolutePunk, we scored these lists using a basic scale that I think Thomas Nassiff originally came up with. When there were 30+ staff members all contributing, it worked pretty well to give a basic structure to what albums were the most popular amongst staff members. I never really gave much thought to it, and it’s been passed down and continued to be used by different contributors that help put together all of the various lists here on the website. Last week I got the itch to re-think this process.
{kind=link}
I started by researching all the various ways you can vote for and rank things. From the multiple ways award shows do it, to election models, to all the math-stat-nerd stuff I could understand. My biggest takeaway was that there’s no perfect way to do this. Every method has pros and cons, and a lot of it comes down to what features are most important to you in how you devise a system to be most “fair.” With that in mind, I decided to create a new algorithm that we could use going forward on all of our contributor fueled ranking lists. The downside of the method we were using was far more apparent with a much smaller staff pool; albums that were ranked at number one, but only appeared on a few lists, ended up having outsized point values. What I set out to do was create an algorithm that had the goal of looking at consensus amongst staff members around albums, took into account where those albums were on each staff member’s list, and would rank the albums based upon what the year looked like as a whole from contributors. So, in a year where there’s a lot of consensus, that would be taken into account, but in a year where there’s a whole lot of unique albums, and fewer are showing up multiple times, it would take that into account as well. The result is a ranking system that still gives a lot of points to highly ranked albums on lists, but can account for that album showing up on very few individual lists when other albums have more of a staff consensus around them. Therefore, the final list feels, to me at least, more representative of what the contributors were listened to and loving at that time.
What I’d like to do here is detail a little bit more about the process in order to have a page to link to at the bottom of every ranking post in the future to explain what’s happening transparently and openly and be clear about the goals and design of this system. Then I’d like to share some of the results of the new algorithm on some of the data sets I ran it on. Not to “redo” any of the lists from the past years; I’m not going to replace them, but instead because it’s fascinating (to me at least) to see the results and how different priorities in weighting and ranking can put together often very similar, and often very different, results.
For each list, contributors come up with their favorite albums of the year on their own. We don’t sit around and talk about what records would best define the website for the year, or what should be where on the list, or even limit the list of albums that can be picked. It’s just a bunch of individual lists that get ranked in a spreadsheet indicating that individual’s favorite albums for the year. This is how we start. Then, I take all of these lists and put them into the ranking system. This system begins by converting each of the “ranks” into a score based on a logarithmic scale. Lower ranked albums are worth fewer points. Then bonus points are added based upon various factors, such as the album appearing on multiple lists, the average score, how many unique albums there were in a given year, how much consensus was built around albums as a whole, and a few other things. Albums higher on the lists and on more lists generally do the best. I most certainly over-engineered the shit out of this, but I think the end result is the fairest representation of my stated goal. I know nothing like this is “perfect,” and someone else may have written a ranking system that has different priorities. But, for me, I like seeing what albums are the most representative of the staff best correlated to their passion for them. I think this system, prioritizing consensus a tad more, but also making sure to take into account how high an album is on a list, does a pretty good job of balancing that line and scales well interdependent of how many staff members are contributing.
In the future, I think I will end up sharing, in a separate post a few days later (or probably in my newsletter), the final raw data from this system for the number nerds who are curious about things like this. I think it’s fun to look at just how close specific calls were and see how the system determined the higher rank. (While I was making this, I pulled out some of the extra data so I could watch what it was doing and ended up finding that sort of stuff interesting.)
Here are the results of the new algorithm on various data sets. Again, this is not meant to replace any of the previous lists; I’ll only be using this system going forward. However, I think it’s fun to see what changes the algorithm would have made verses our older model and just how close some of these albums were to each other.
2019
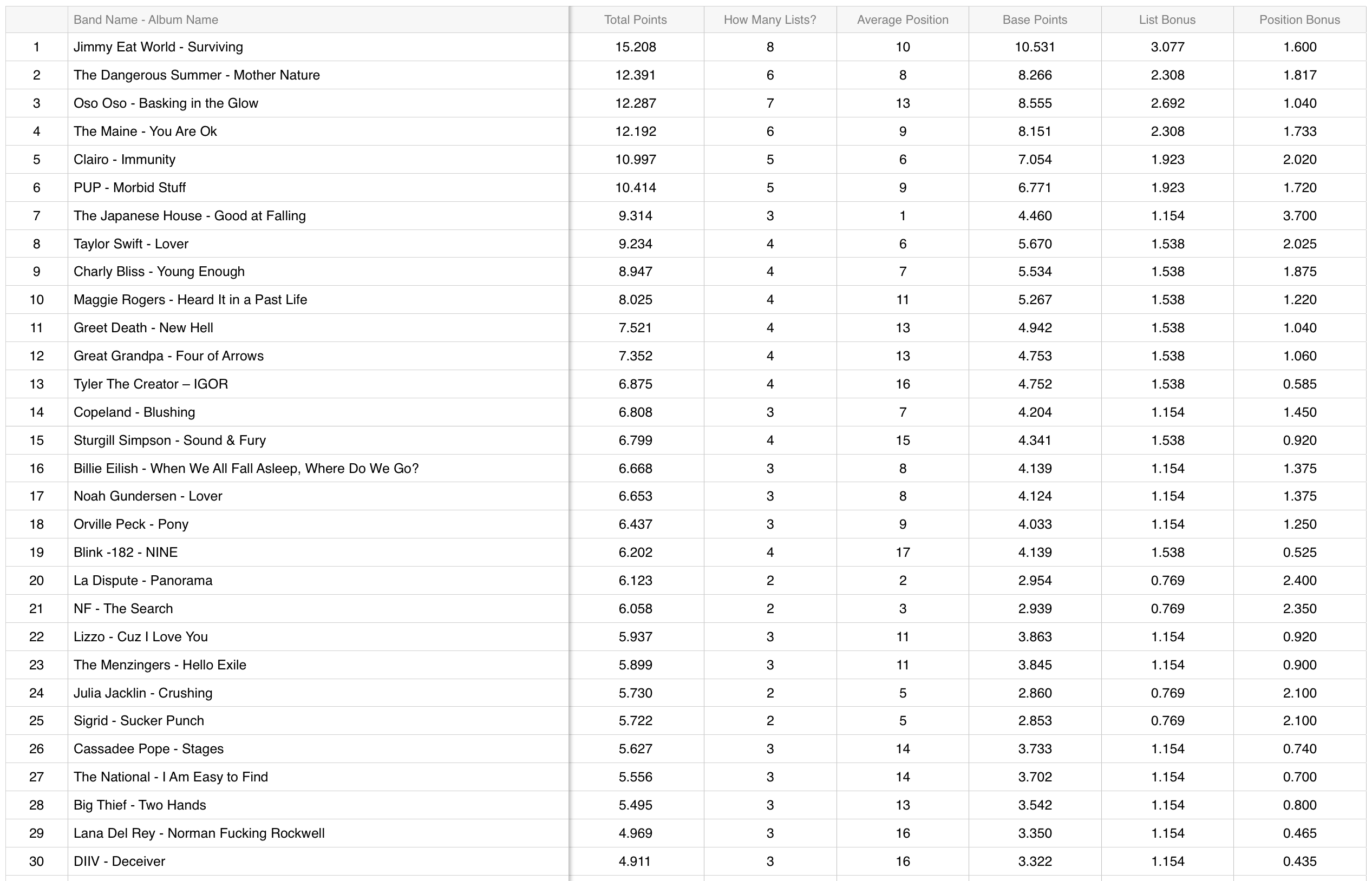
The original list can be found here.
Best of the Decade
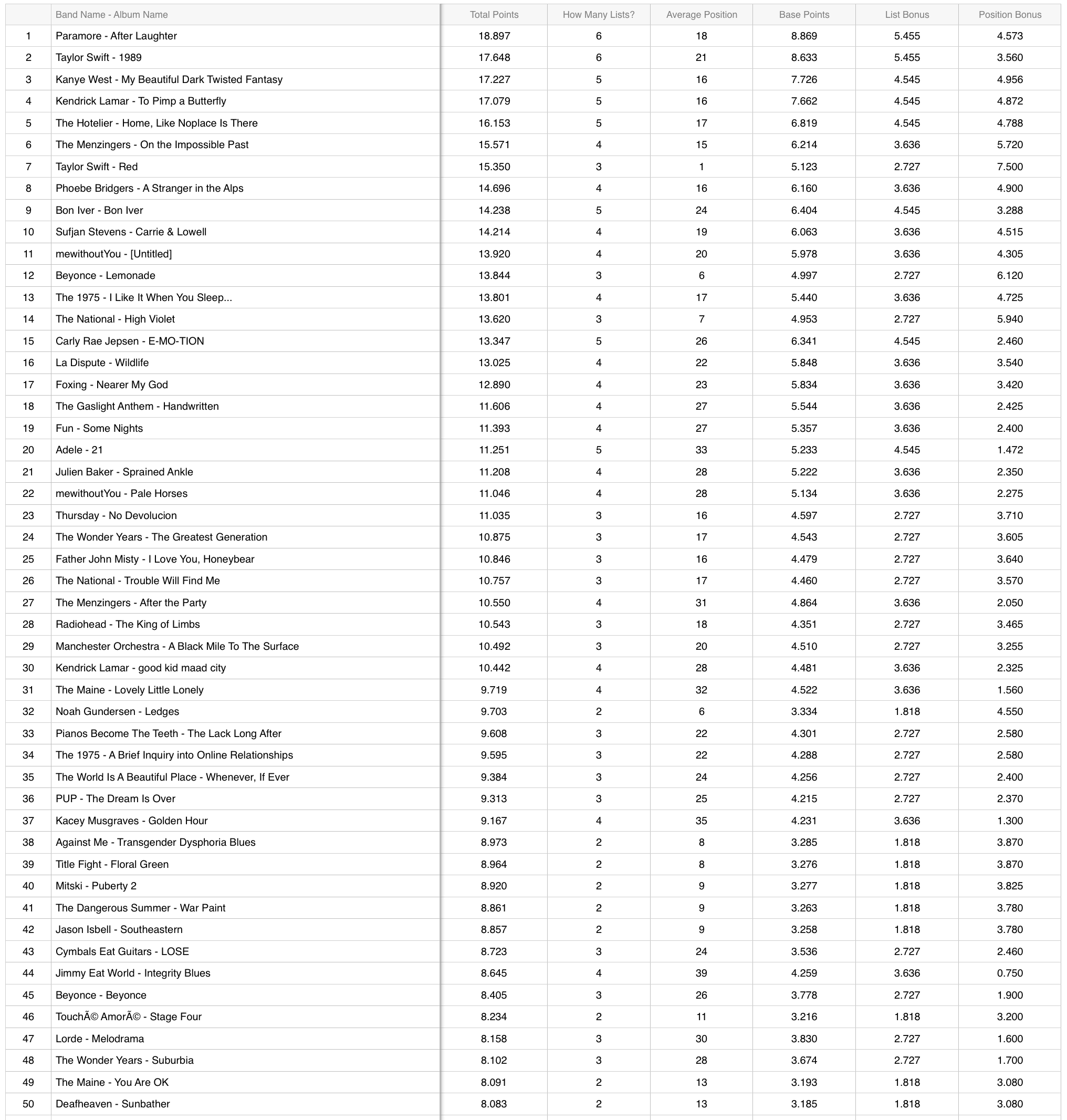
The original list can be found here.
2018
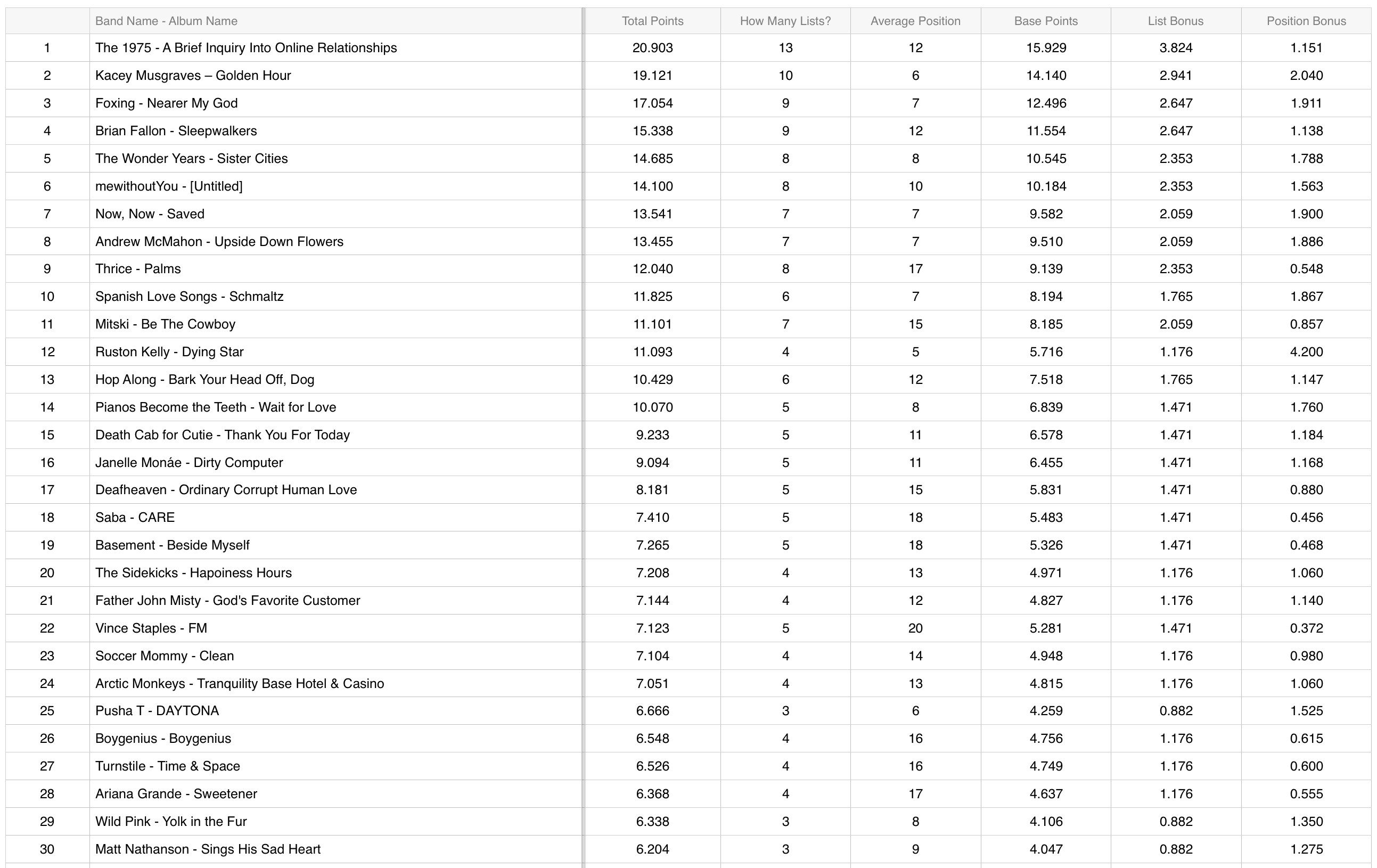
The original list can be found here.
2017
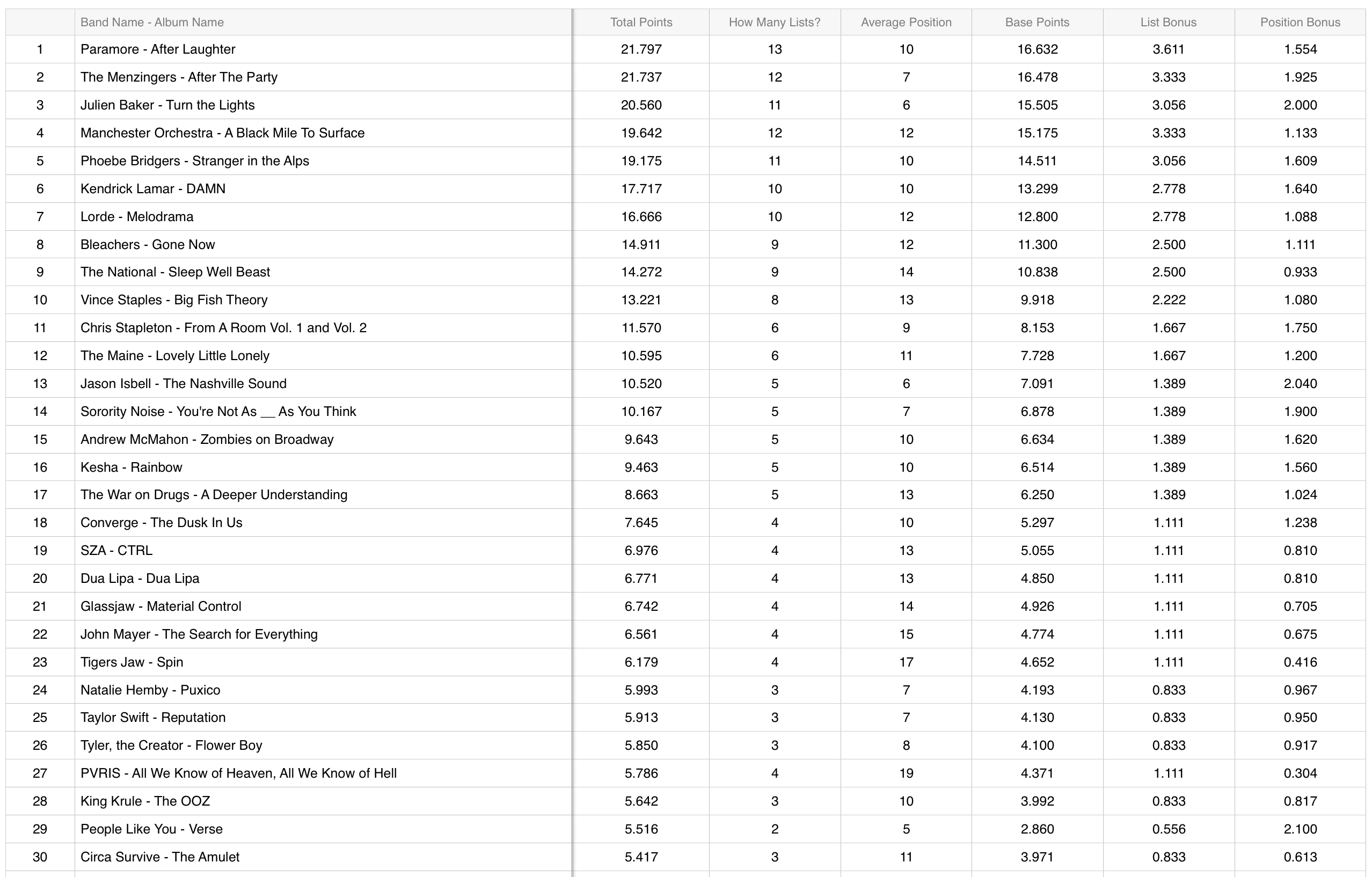
The original list can be found here.
2016
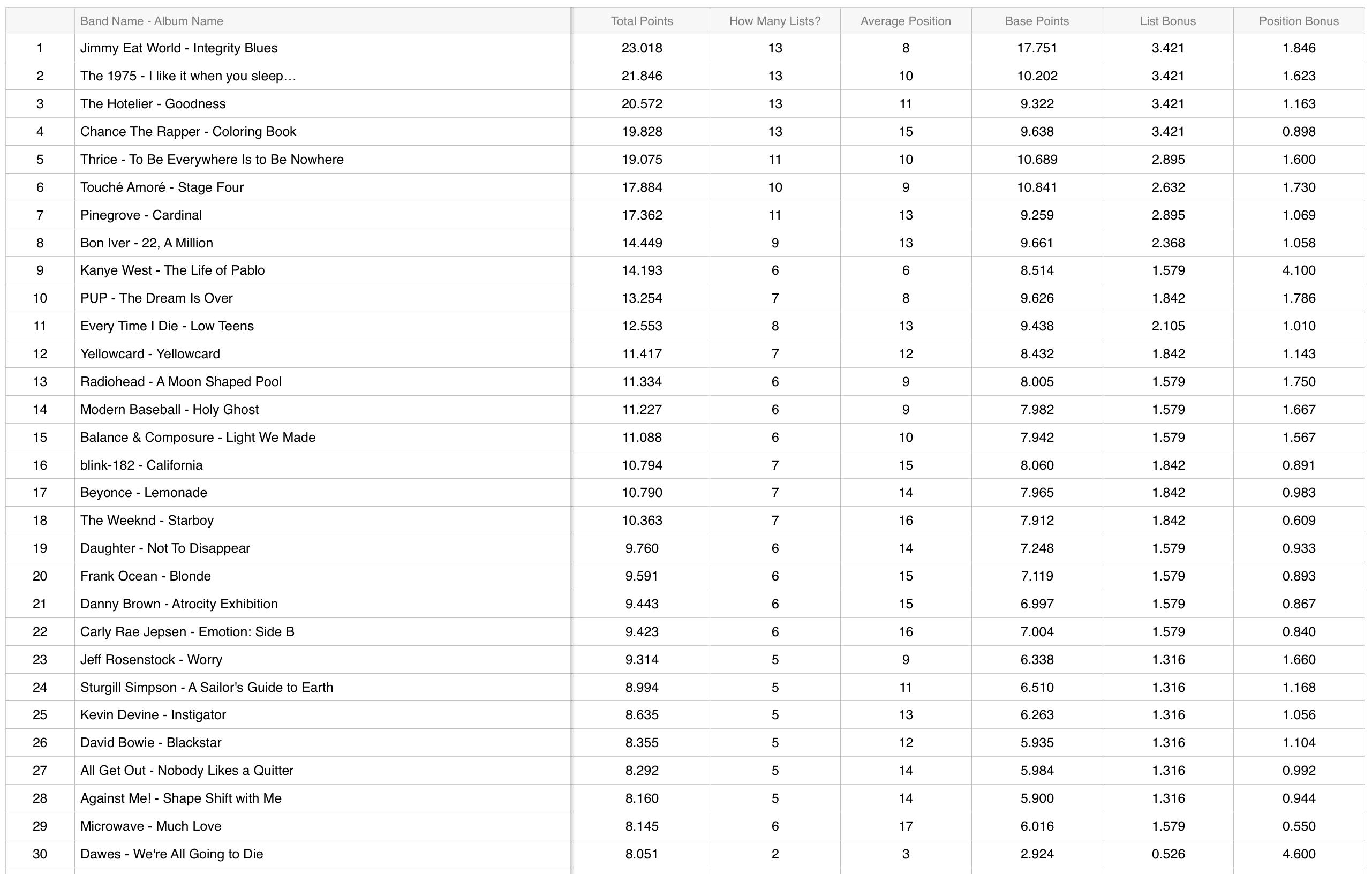
The original list can be found here.
I hope those that made it this far into the post found some of this information as interesting as I did. At the very least I enjoyed the mental exercise and like the consistency we’ll have in the future with calculating and then publishing our never-ending-cascade-of-lists.